Conclusion
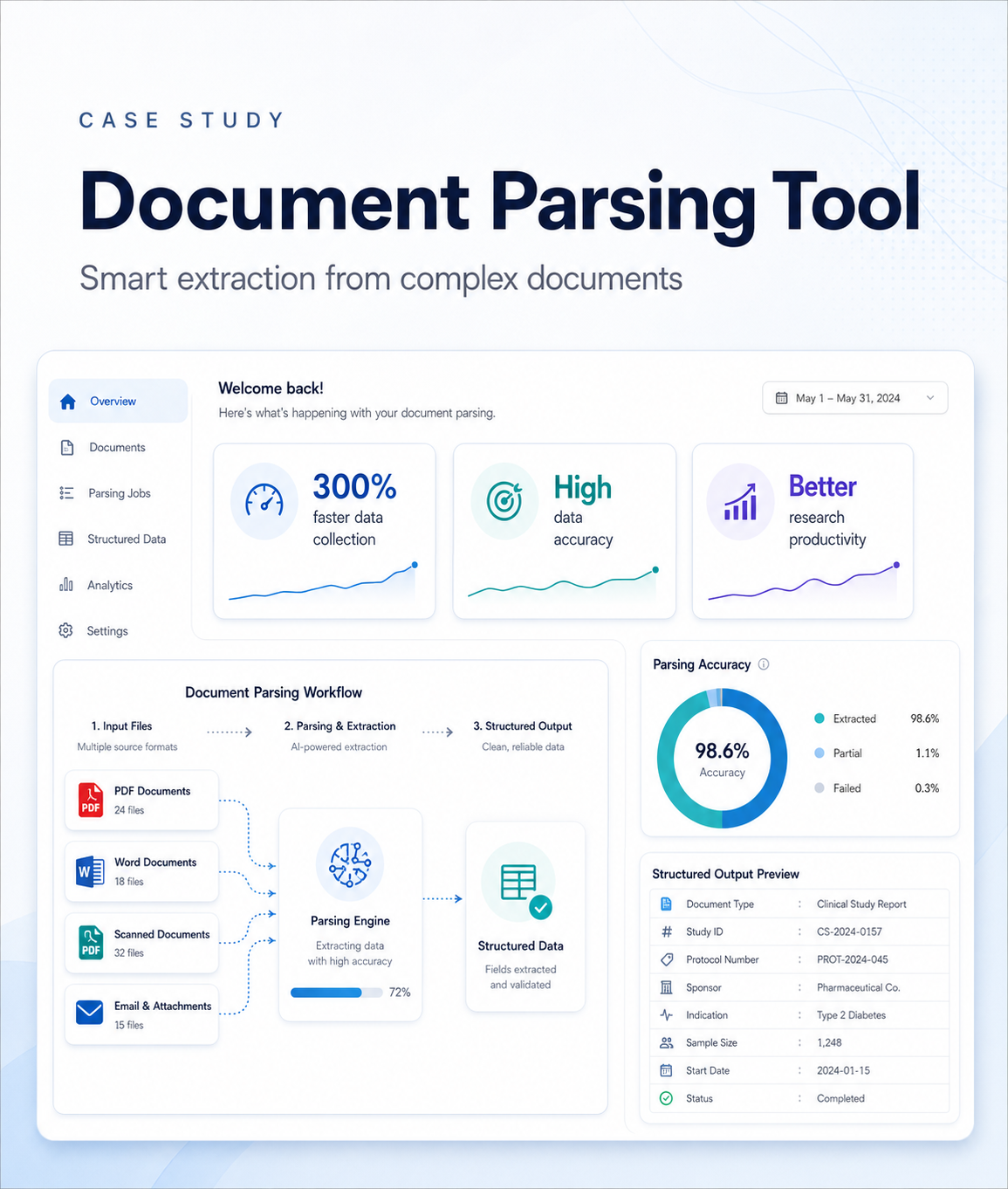
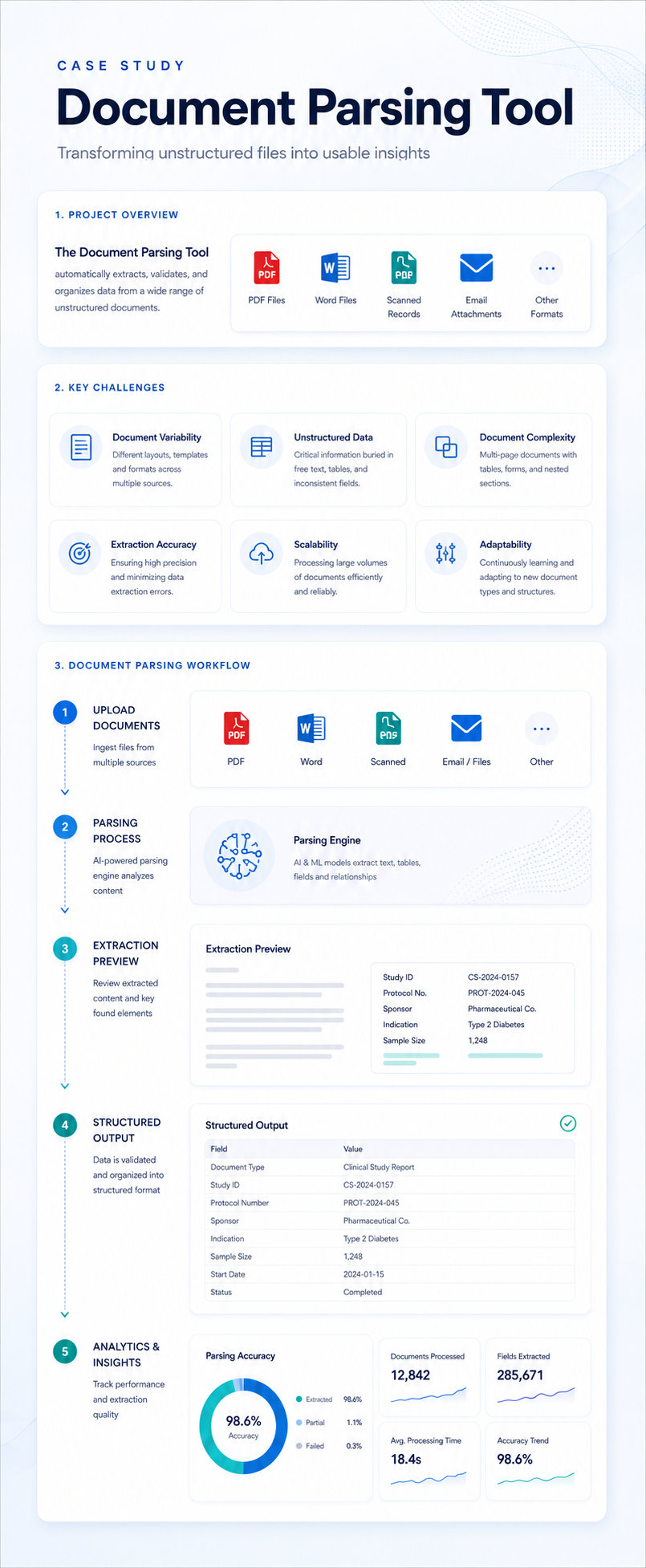
The customized document parser successfully addressed document variability, unstructured content challenges, and scalability needs through a dynamic, reliable, and adaptable solution.
By combining advanced NLP, customizable extraction templates, quality assurance, and integration readiness, the system improved data reliability, sped up workflows, and delivered more usable information across research and regulatory processes.
This updated version now places the old IQVIA content into your new design format while keeping the page responsive, clean, and suitable for dynamic content changes.
- Old content placed in the new case study design
- CloudFront URLs replaced with Azure Edge base URL
- Same premium `csd-*` structure maintained
- Proper responsive dynamic-content-friendly layout